Introducción
El algoritmo K-Means es una técnica popular de agrupamiento en el análisis de datos. En este blog, exploraremos qué es el algoritmo K-Means, cómo funciona y proporcionaremos un ejemplo práctico para comprenderlo mejor.
¿Qué es el Algoritmo K-Means?
El algoritmo K-Means es un método de agrupamiento no supervisado que divide un conjunto de datos en grupos, o "clusters", basándose en similitudes entre las observaciones. El objetivo es clasificar los datos en grupos coherentes, donde las observaciones dentro de un grupo son más similares entre sí que con las observaciones en otros grupos.
Nota: sí aun no conoces que son los "clusters" puedes conocer mas acerca de ellos haciendo clic en el siguiente botón:
¿Cómo funciona el Algoritmo K-Means?
- Inicialización de Centroides: Selecciona aleatoriamente K centroides iniciales, donde K es el número de clusters deseado.
- Asignación de Puntos a los Clusters: Asigna cada punto de datos al cluster cuyo centroide está más cercano.
- Actualización de los Centroides: Recalcula los centroides de cada cluster tomando la media de todos los puntos asignados a ese cluster.
- Repetición: Repite los pasos 2 y 3 hasta que los centroides no cambien significativamente o se alcance un criterio de convergencia.
Ejemplo práctico
En este ejemplo aplicaremos el algoritmo K-Means a un conjunto de datos de ejemplo generado aleatoriamente. Veremos cómo el algoritmo agrupa los datos en clusters basados en similitudes, y visualizaremos los resultados para comprender mejor la distribución de los datos y la ubicación de los centroides de los clusters.
- Aplicaremos el algoritmo K-Means en Python utilizando la biblioteca scikit-learn. Si aún no está instalada en tu entorno de Python. Puedes instalar scikit-learn utilizando pip, que es el administrador de paquetes de Python estándar. Aquí tienes cómo hacerlo: Ejecuta esta instrucción en la terminal para instalar las bibliotecas necesarias.
pip install numpy matplotlib scikit-learn
- Utiliza el siguiente codigo:
# Importar las bibliotecas necesarias
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
# Generar datos de ejemplo
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# Visualizar los datos de ejemplo
plt.scatter(X[:, 0], X[:, 1], s=50)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Datos de ejemplo')
plt.show()
# Crear el objeto KMeans
kmeans = KMeans(n_clusters=4)
# Ajustar el modelo a los datos
kmeans.fit(X)
# Obtener las etiquetas de los clusters y los centroides
labels = kmeans.labels_
centroids = kmeans.cluster_centers_
# Visualizar los clusters y los centroides
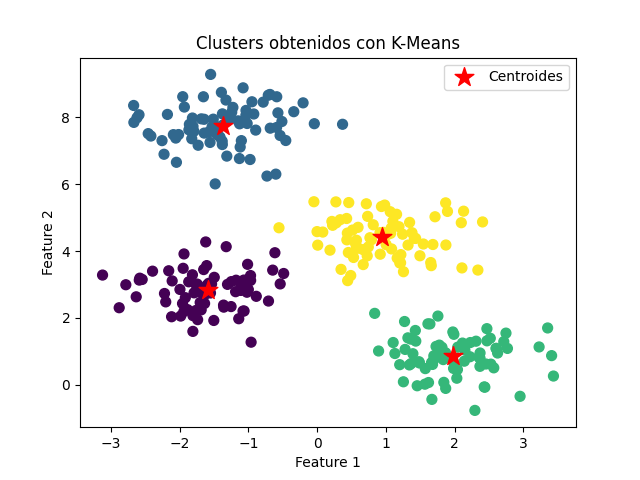
plt.scatter(X[:, 0], X[:, 1], c=labels, s=50, cmap='viridis')
plt.scatter(centroids[:, 0], centroids[:, 1], marker='*', s=200, c='red', label='Centroides')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Clusters obtenidos con K-Means')
plt.legend()
plt.show()
Resultado
¿Qué es el algoritmo K-means?