Introducción:
La reducción de dimensionalidad es una técnica esencial en el análisis de datos, especialmente en conjuntos de datos grandes y complejos. Una técnica relativamente nueva que ha ganado popularidad en este campo es UMAP, que significa "Mapeo Uniforme de Aproximación y Proyección" por sus siglas en inglés. Aunque UMAP es conocido principalmente por su uso no supervisado, su versión supervisada ofrece un enfoque poderoso para la visualización y análisis de datos con etiquetas.
¿Qué es UMAP Supervisado?:
UMAP supervisado es una extensión del algoritmo de reducción de dimensionalidad UMAP que incorpora información de etiquetas de clase en el proceso de mapeo. A diferencia del UMAP no supervisado, que solo se basa en la estructura de los datos, UMAP supervisado utiliza las etiquetas de clase para guiar la proyección de los datos en un espacio de menor dimensión.
Ventajas de UMAP Supervisado:
Preservación de la estructura global y local: UMAP supervisado conserva tanto la estructura global como la local de los datos, lo que permite una representación fiel de las relaciones entre las instancias tanto a nivel macro como micro.
Eficiencia computacional: UMAP supervisado es conocido por su eficiencia computacional, lo que lo hace adecuado para conjuntos de datos grandes y de alta dimensionalidad.
Flexibilidad en la interpretación: Al integrar la información de las etiquetas de clase, UMAP supervisado proporciona una visualización que es más interpretable en términos de las relaciones entre las clases y sus distribuciones en el espacio de menor dimensión.
Características Clave:
Funcionalidad Supervisada: Utiliza información de etiquetas de clase para guiar la proyección de los datos.
Preservación de la Estructura: Conserva tanto la estructura global como local de los datos originales.
Escalabilidad: Apto para conjuntos de datos grandes y de alta dimensionalidad.
Interpretación Mejorada: Facilita una interpretación más clara de las relaciones entre clases y la distribución de datos.
Ejemplo
Cómo Aplicar UMAP Supervisado en Python
Paso 1: Instalar las Bibliotecas Necesarias:
Antes de comenzar, asegúrate de tener instaladas las bibliotecas umap-learn, scikit-learn y matplotlib. Puedes instalarlas fácilmente utilizando pip ejecutando el siguiente comando en tu terminal:
pip install umap-learn scikit-learn matplotlib
Paso 2: Cargar y Preprocesar los Datos:
En este ejemplo, utilizaremos el conjunto de datos de dígitos escritos a mano, disponible en la biblioteca scikit-learn. Importamos los datos y los dividimos en conjuntos de entrenamiento y prueba utilizando la función train_test_split. Luego, normalizamos los datos utilizando StandardScaler para asegurarnos de que todas las características tengan la misma escala.
Paso 3: Aplicar UMAP Supervisado:
Utilizaremos la implementación de UMAP proporcionada por la biblioteca umap-learn. Configuraremos el modelo con los parámetros deseados, como el número de componentes (n_components), el número de vecinos (n_neighbors) y la distancia mínima (min_dist). Luego, aplicaremos UMAP supervisado utilizando la función fit_transform, pasando los datos de entrenamiento y las etiquetas de clase correspondientes.
Paso 4: Visualizar los Resultados:
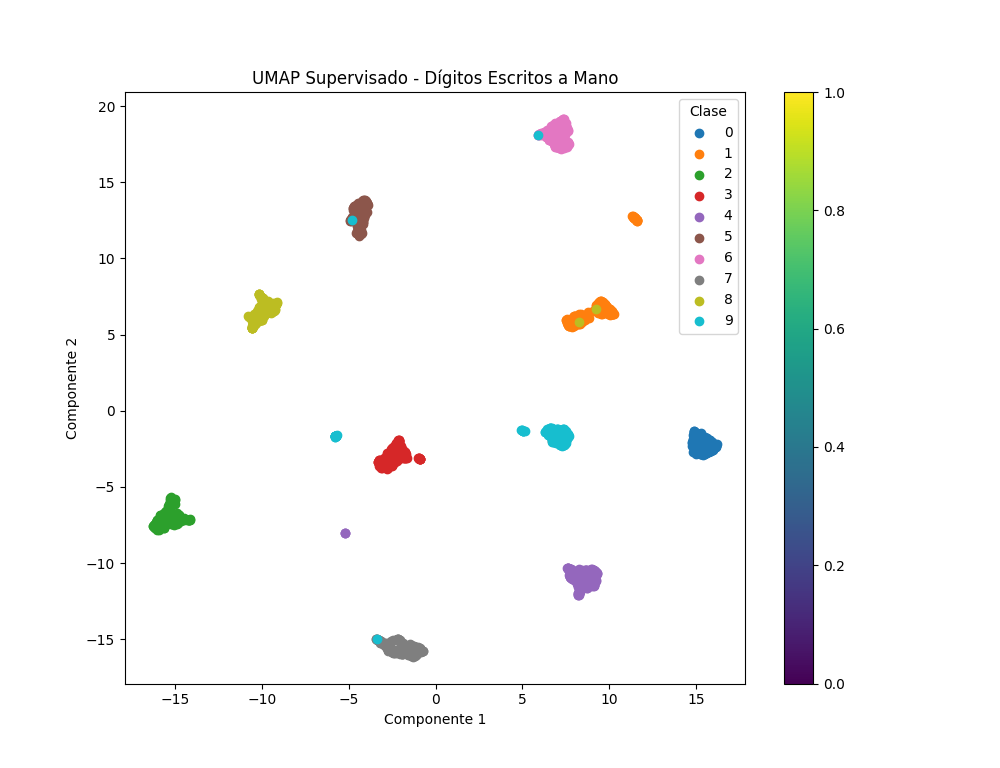
Finalmente, visualizaremos los datos reducidos en un espacio bidimensional utilizando un diagrama de dispersión. Cada punto en el gráfico representa una instancia de los datos, y los puntos se colorearán según la clase a la que pertenecen. Esto nos permitirá visualizar la distribución de los datos en un espacio de menor dimensión conservando la estructura de las clases.
Te dejo aqui el codigo:
# Paso 1: Importar las bibliotecas necesarias
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from umap import UMAP
# Paso 2: Cargar y preprocesar los datos
digits = load_digits()
X = digits.data
y = digits.target
# Dividir el conjunto de datos en entrenamiento y prueba
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Normalizar los datos
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Paso 3: Aplicar UMAP supervisado
umap_supervised = UMAP(n_components=2, n_neighbors=10, min_dist=0.1)
embedding = umap_supervised.fit_transform(X_train_scaled, y_train)
# Paso 4: Visualizar los resultados
plt.figure(figsize=(10, 8))
for i in range(10): # Supongamos que tenemos 10 clases
plt.scatter(embedding[y_train == i, 0], embedding[y_train == i, 1], label=str(i))
plt.title('UMAP Supervisado - Dígitos Escritos a Mano')
plt.xlabel('Componente 1')
plt.ylabel('Componente 2')
plt.legend(title='Clase')
plt.colorbar()
plt.show()
Resultado
¿Qué es UMAP supervisado?