Introducción.
Imagina que eres un programador y desea realizar una gran base de datos donde se puedan almacenar el nombre, correo, experiencia, y puesto de los empelados de toda una empresa; para muchos la forma mas fácil de hacerlo seria crear un arreglo de objetos tipo Empleado, en donde se almacenaran los datos.

Si bien no es mala idea, imagine que esa empresa es Walmart, Amazon o Oxxo, donde se tienen millones de empleados, si desea buscar los datos de un empleado en su arreglo tendría que compara el nombre del empleado con cada elemento del arreglo, y si tiene surte se encontrara en índice 0 o 200, pero en el peor de los caso podría ser el índice 12 millones o 20 millones .
Ahora imagine que es día de paga y tiene por tienda 100 empleados y por búsqueda tarda solamente en promedio 5 minutos, tendría dedicar 500 minutos ósea 8 horas con 20 minutos aproximadamente para por pagarle a sus empleados, y así mismo tendría gastos enormes de electricidad y vida útil de sus equipos de computo.
Como muchos problemas en la vida ya existe alguien que ideo una solución para esta problemática esta solución son las tablas Hash y ese alguien fue Hans Peter Luhn, un científico de IBM .
Tablas Hash.
Las tablas Hash, también conocidas como Diccionarios, Tablas de dispersión, mapas, son estructuras de datos, que se utilizan para almacenar y recuperar datos de manera eficiente. La idea principal de las tablas hash es asociar claves o llaves con valores esto mediante una función hash.
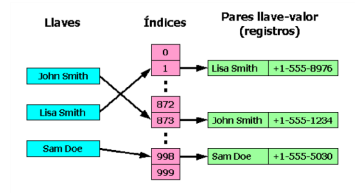
Operaciones de una tabla Hash.
Inserción: Agregar un nuevo elemento (clave-valor) a la tabla hash.
Búsqueda: Buscar un elemento específico en la tabla hash utilizando su clave y recuperar su valor asociado.
Eliminación: Eliminar un elemento específico de la tabla hash según su clave.
Funciones Hash.
Una función Hash es cualquier función que tome una llave "key" y la convierta en un índice de un arreglo.
Existen muchas funciones que se utilizan para el Hashing, a continuación te presentamos algunas de estas:
Método de la división: En este método, se utiliza la operación de división para calcular el índice de la tabla hash. La clave se divide por el tamaño de la tabla hash y el residuo de esta división se toma como el índice. Por ejemplo, si tenemos una tabla hash de tamaño 10 y la clave es 25, el índice se calcularía como 25 % 10 = 5.
Método mid-square: En este método, se toma la clave, se eleva al cuadrado y luego se toman los dígitos centrales como el índice de la tabla hash. Por ejemplo, si la clave es 256, su cuadrado es 65536 y si tomamos los dígitos centrales obtenemos el número 55, que podría ser utilizado como índice en la tabla hash.
Método de la Suma: En este método, se suman los valores ASCII de los caracteres en la clave y luego se toma el residuo de esta suma dividida por el tamaño de la tabla hash. Este residuo se utiliza como el índice en la tabla hash.
Existen otros métodos considerados en la categoría de folding.
Folding: metodo en el que se toma la llave y "se dobla", o se parte y se combinan las partes para formar un índice dentro del arreglo.
String folding: En este método, se toman secciones de la clave, se convierten en números (a menudo utilizando su valor ASCII) y luego se suman o combinan para formar el índice.
Integer folding (Plegado de Enteros): Similar al plegado de cadenas, pero se aplica a las representaciones numéricas de las claves en lugar de a las cadenas de caracteres.
Colisiones.
Es cuando dos llaves diferentes resultan en un mismo índice en el arreglo. Existen varias técnicas comunes para solucionar colisiones en tablas hash. Algunas de ellas son:
1. Encadenamiento Separado:
En este método, cada elemento de la tabla hash contiene una lista enlazada de todos los elementos que tienen la misma ubicación (hash). Cuando ocurre una colisión, el nuevo elemento se agrega a la lista enlazada correspondiente en esa ubicación.2.
2. Resolución de Colisiones por Dispersión Abierta (Open Addressing):
En este enfoque, cuando ocurre una colisión, se busca otra ubicación dentro de la tabla hash para colocar el elemento. Esto puede hacerse utilizando técnicas como:
- Sondeo Lineal: El algoritmo busca secuencialmente las ubicaciones siguientes hasta encontrar una disponible.
- Sondeo Cuadrático: El algoritmo utiliza una secuencia de incrementos cuadráticos para buscar ubicaciones alternativas.
- Doble Dispersión: Se calcula una segunda función hash para determinar la próxima ubicación en caso de colisión.
4. Rehashing:
En este enfoque, cuando la tabla hash alcanza cierto factor de carga (una proporción entre el número de elementos y el tamaño de la tabla), se crea una nueva tabla hash con un tamaño mayor y se reorganizan los elementos existentes en la nueva tabla utilizando una nueva función hash.
5. Coalescencia de Dispersión (Clustering):
Este método intenta resolver colisiones agrupando los elementos que chocan en áreas específicas de la tabla. Luego, cuando ocurre una búsqueda, se examina el área antes de continuar la búsqueda.
¿ Que son las Tablas Hash ?